Description
Question answering over knowledge graphs and other RDF data has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, systems from the IR and NLP communities have addressed QA over text, but such systems barely utilize semantic data and knowledge. This paper presents the first QA system that can seamlessly operate over RDF datasets and text corpora, or both together, in a unified framework. Our method, called UNIQORN, builds a context graph on-the-fly, by retrieving question-relevant triples from the RDF data and/or snippets from the text corpus using a fine-tuned BERT model. The resulting graph is typically rich but highly noisy. UNIQORN copes with this input by advanced graph algorithms for Group Steiner Trees, that identify the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that UNIQORN produces results comparable to the state-of-the-art on KGs, text corpora, and heterogeneous sources. The graph-based methodology provides user-interpretable evidence for the complete answering process. A running example in this paper is:
Question: director of the western for which Leo won an Oscar? [Answer: Alejandro Iñàrritu]
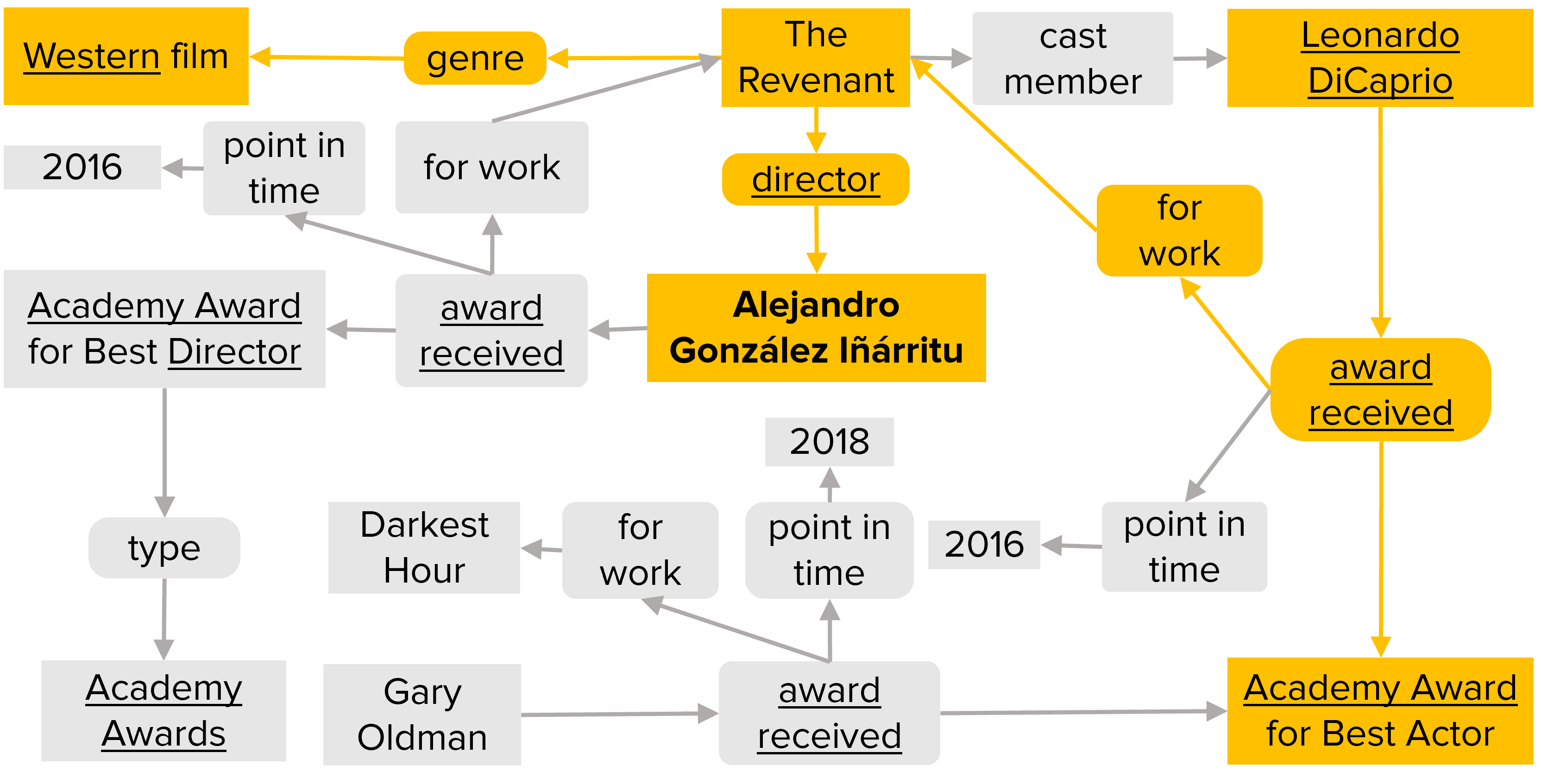
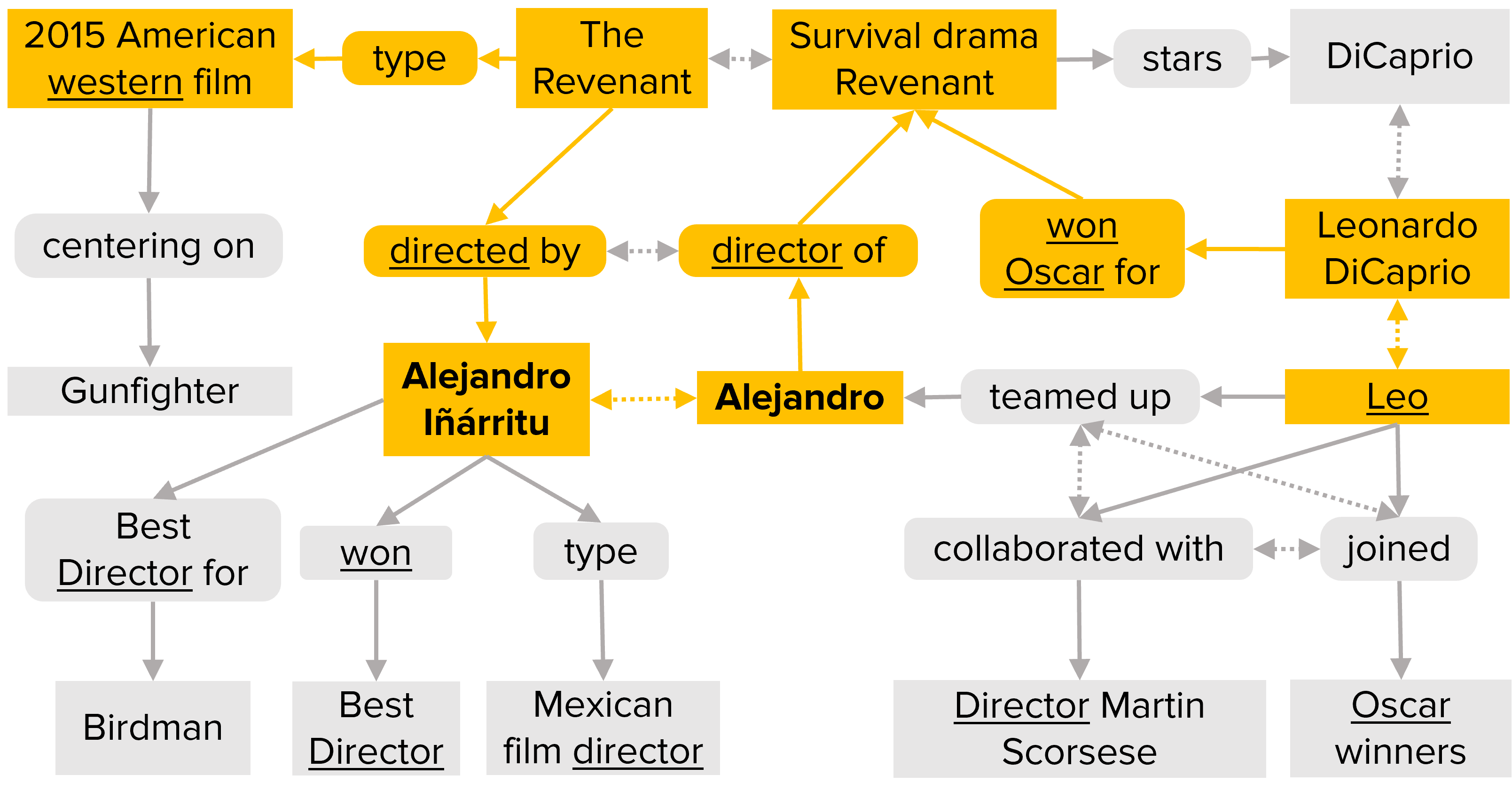
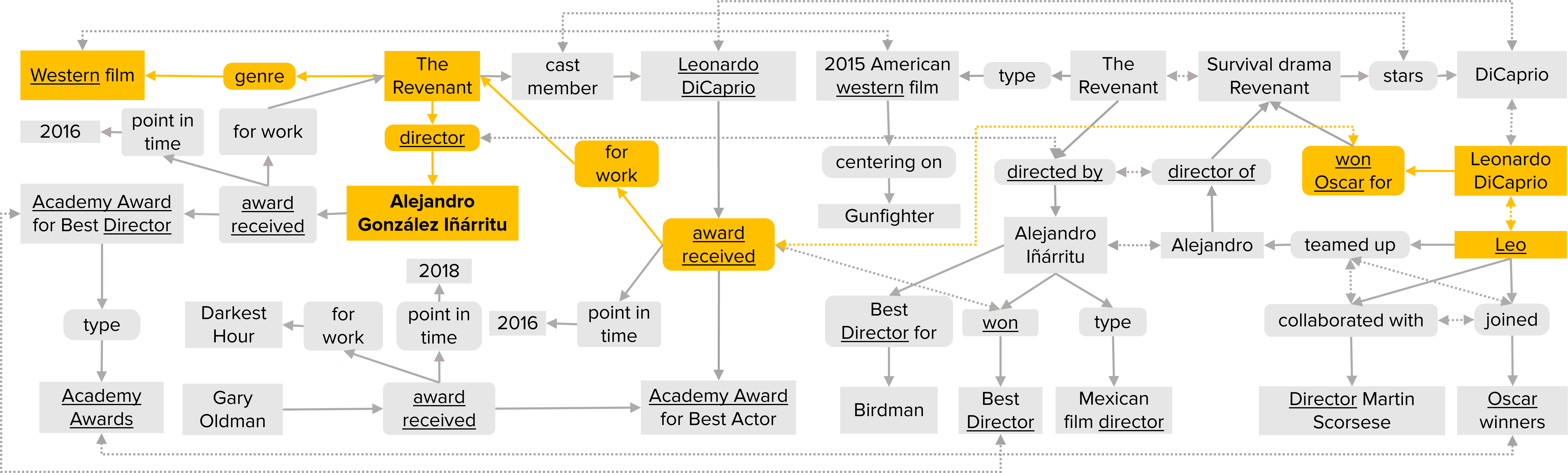
Please refer to our paper for further details.
Contact
For more information, please contact: Soumajit Pramanik, Jesujoba Alabi, Rishiraj Saha Roy or Gerhard Weikum
To know more about our group, please visit https://qa.mpi-inf.mpg.de.
Demo
Please select a source corpus, and then choose a question from the drop-down list. You can also click to randomly choose a question from the list.
Top-1 UNIQORN answers to questions from 6 benchmarks
LC-QuAD 2.0 (Dubey et al. 2019) [All 4,921 test questions]LC-QuAD 1.0 (Trivedi et al. 2017) [1,459 complex questions]
ComQA (Abujabal et al. 2019) [202 complex questions]
QALD (Usbeck et al. 2018) [70 complex questions]
CQ-W (Abujabal et al. 2017) [150 complex questions]
CQ-T (Lu et al. 2019) [150 complex questions]